IDP – Intelligent Document Processing
Inhalt
- Definition of Intelligent Document Processing
- Background: How did IDP Come About?
- The Core Components of IDP
- How Does Intelligent Document Processing Work? The Process in 6 Steps
- Key IDP Terms from A to Z
- IDP and Related Technologies: Distinctions
- Typical Use Cases for Intelligent Document Processing
- Intelligent Document Processing and Data Protection: GDPR Basics
- Conclusion: Understanding IDP to Use It Effectively
- Additional Resources
- FAQ: Frequently Asked Questions About IDP Intelligent Document Processing
Inhalt
- Definition of Intelligent Document Processing
- Background: How did IDP Come About?
- The Core Components of IDP
- How Does Intelligent Document Processing Work? The Process in 6 Steps
- Key IDP Terms from A to Z
- IDP and Related Technologies: Distinctions
- Typical Use Cases for Intelligent Document Processing
- Intelligent Document Processing and Data Protection: GDPR Basics
- Conclusion: Understanding IDP to Use It Effectively
- Additional Resources
- FAQ: Frequently Asked Questions About IDP Intelligent Document Processing
Definition of Intelligent Document Processing
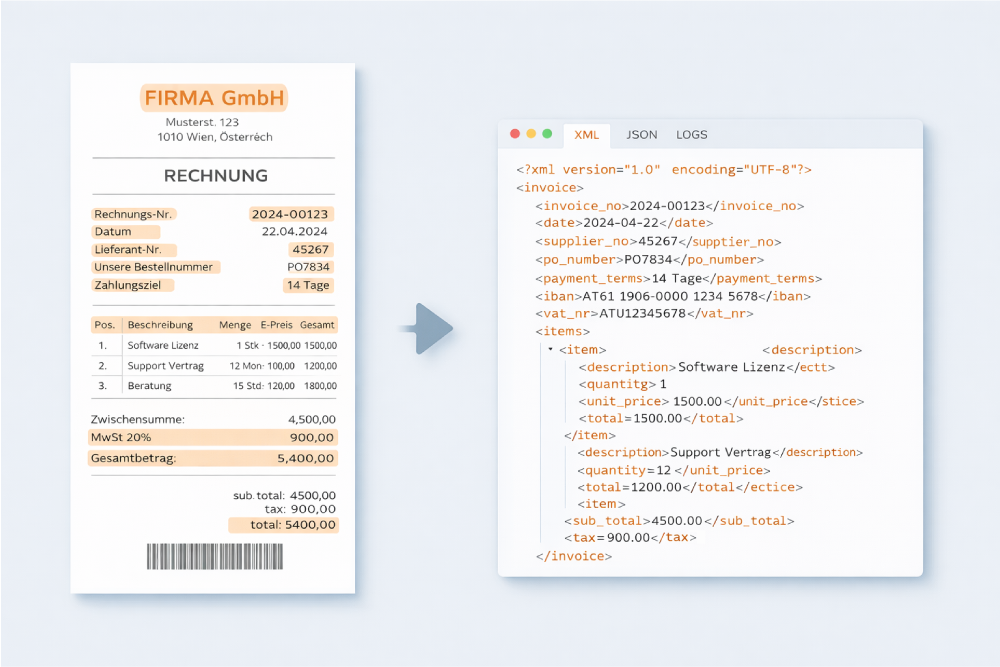
Intelligent Document Processing (IDP) refers to the use of AI technologies for the automated capture, classification, extraction, validation, and further processing of data from structured, semi-structured, and unstructured documents. IDP combines methods such as OCR, machine learning, natural language processing (NLP), and large language models (LLMs) to not only read documents automatically but also understand their content and integrate it into business processes.
IDP is therefore more than just text recognition. It covers the entire processing workflow, from document capture to integration into downstream systems such as ERP, financial accounting, or archiving solutions. Unlike traditional OCR systems or rule-based automation tools, IDP can handle variable layouts, unknown formats, and unstructured content.
Synonyms and related terms: IDP is also referred to as “intelligent document processing,” “AI document automation,” or, in a broader sense, “Intelligent Document Automation.”
Background: How did IDP Come About?
IDP is not the result of a single technological breakthrough, but rather the outcome of several decades of technological evolution. It originated with optical character recognition (OCR), which was developed as early as the 1960s to make printed text machine-readable.
| Development Period | Development Stage |
|---|---|
| 1960s | First OCR systems: character-based text recognition from scanned documents. Very limited accuracy, dependent on font type and resolution. |
| 1990s | Improvements in OCR accuracy through statistical methods. The first commercial systems for automatic document capture emerge. |
| 2000s | Machine learning enables adaptive recognition models. First IDP precursors for structured document types (e.g., invoices from regular suppliers). |
| 2010s | Deep learning and NLP significantly improve contextual understanding. IDP platforms emerge as a standalone product category. |
| From 2022 onward | Large Language Models (LLMs) revolutionize document processing: semantic understanding without prior training on document types. Agentic AI complements IDP with proactive process control. |
The Core Components of IDP
IDP is not a monolithic system, but rather a combination of several AI technologies. The following overview provides a definition of each component.
OCR: Optical Character Recognition
OCR refers to the automatic recognition of printed or handwritten text from image files or scanned documents and its conversion into machine-readable text. Traditional OCR operates on a character-by-character basis and lacks content understanding. It forms the technical foundation of IDP but is not synonymous with IDP. Modern “intelligent OCR” combines traditional text recognition with AI methods to increase accuracy and layout flexibility. We have described more about the development and current state of OCR in the article “OCR from Different Perspectives.”
ML: Machine Learning
Machine learning is a subfield of AI in which systems learn from sample data rather than being explicitly programmed. In the IDP context, ML is used to classify document types, recognize frequently occurring fields, and improve extraction results over time. ML models typically require a training phase for each document type. They are accurate with known formats but vulnerable to unknown or altered layouts.
NLP: Natural Language Processing
Natural Language Processing refers to AI methods that enable computers to understand, analyze, and generate human language. In the IDP context, NLP is used to capture semantic relationships in documents: What type of document is it? What does a specific text segment mean in the overall context? NLP bridges the gap between character-based recognition (OCR) and content understanding (LLM).
LLM: Large Language Model
Large Language Models (LLMs) are AI models that have been trained on very large text corpora and thus understand natural language and context at a significantly higher level than traditional ML or NLP models. In the IDP context, LLMs enable the processing of unknown document layouts without prior training, the semantically correct recognition of field contents (e.g., “excl. VAT” = net amount), the interpretation of ambiguous or unstructured text passages, and the answering of questions about documents in natural language. Well-known LLMs include GPT-4 (OpenAI), Claude (Anthropic), Gemini (Google), and various open-source models.
Agentic AI
Agentic AI refers to AI systems that not only respond to requests but also proactively make decisions, plan tasks, and independently initiate follow-up processes. In the context of IDP, this means: The system recognizes an incoming document, forwards it after classification, automatically checks for discrepancies, approves it without manual intervention if it complies with rules, and escalates specific exceptions. Agentic AI represents the current state-of-the-art in IDP technology.

How Does Intelligent Document Processing Work? The Process in 6 Steps
A complete IDP process typically includes the following phases. Depending on the solution and use case, individual steps may be combined or expanded.
Solutions for Intelligent Document Automation
Key IDP Terms from A to Z
The following list defines the most important technical terms that frequently appear in the context of IDP.
AI systems that proactively and autonomously make decisions and initiate processes without needing to be manually prompted at every single step. In the IDP context, Agentic AI independently manages the entire document workflow, from recognition and validation to archiving.
The storage of business documents in a format that prevents subsequent alterations and meets accounting and compliance requirements. In Germany and Austria, the Principles of Proper Accounting (GoB), as well as the GoBD (Germany) and the Austrian BAO, are applicable. Audit-proof archiving is typically the final step in an IDP process.
A general term for the automated capture and interpretation of business documents (invoices, expense reports, order confirmations, delivery notes, etc.) by AI-powered systems. It encompasses text recognition, classification, field extraction, and validation. It is often used interchangeably with IDP in the context of document-based accounting and procurement processes.
A subfield of AI that enables computers to interpret image content. In the IDP context, computer vision is used to analyze document layouts, recognize tables, locate fields, and process images or stamps within documents. Computer vision complements OCR by adding visual structure recognition.
The process of automatically identifying relevant information from a document and converting it into a structured format. In IDP systems, data extraction involves both the recognition of known fields (e.g., invoice number, amount, date) and the contextual understanding of unknown document structures.
Related terms: Field extraction, key-value extraction, Named Entity Recognition (NER)
The automatic classification of a document into a predefined category (e.g., incoming invoice, order confirmation, delivery note, expense receipt). IDP systems use a combination of content analysis (NLP), visual structure recognition (computer vision), and machine learning (ML) to achieve this. Correct classification is a prerequisite for all subsequent processing steps.
Refers to the complete automation of a business process, from document receipt through all processing steps to integration into target systems and audit-proof archiving, without any media breaks or manual intermediate steps. In the context of IDP, end-to-end automation is the benchmark against which solutions are measured.
A language model trained on massive amounts of text, enabling it to understand natural language at a semantic level. LLMs can generate text, summarize, classify, and answer questions. In IDP applications, they enable the processing of unknown layouts and context-based understanding of document content without prior document-specific training. Well-known LLMs: GPT (OpenAI), Claude (Anthropic), Gemini (Google).
A subfield of artificial intelligence. ML-based systems learn from sample data. Instead of relying on fixed rules, they identify patterns in document layouts and can accurately parse them as long as the document adheres to known patterns. In the IDP context, they are used for document classification, field extraction from known templates, and continuous improvement of recognition quality through user feedback.
An interruption in the flow of information caused by switching from one medium or system to another, which requires manual data entry. Example: A PDF invoice is received via email but must be manually entered into the ERP system. Eliminating all media breaks is a key objective of IDP solutions.
A subfield of AI focused on the automatic processing and analysis of human language. NLP methods enable the recognition of text structures, semantic relationships, and linguistic meanings. In the IDP context, NLP forms the basis for understanding the content of documents beyond mere character recognition.
Technology for converting printed or handwritten text from image files or scans into machine-readable text. Traditional OCR operates on a character-by-character basis without understanding the content. Modern “intelligent OCR” incorporates AI methods to increase accuracy and flexibility. OCR is an essential component of IDP, but on its own it is not a sufficient tool for complex document processes.
Further reading: Our article “OCR Text Recognition from Different Perspectives”
Technology for automating rule-based, repetitive tasks using software robots (bots) that mimic user actions in digital systems. RPA works best with structured data and clearly defined rules. IDP and RPA complement each other: IDP converts unstructured documents into structured data, and RPA processes that data further. RPA cannot interpret unstructured content on its own.
IDP is not RPA! RPA is rule-based, while IDP is adaptive and context-based.
A term used to describe business processes that run entirely automatically in the background without any manual intervention, and without a case worker seeing or controlling the process. Originally originating in the insurance industry, it is now a central goal of every IDP project. The proportion of fully automated processes is measured as the “STP rate.” Partially automated processes, in which humans intervene at defined exception points, are sometimes referred to as “gray processing.”
Data available in a defined, machine-readable format, such as XML, JSON, or database fields. Structured invoice formats like XRechnung or ZUGFeRD provide structured data. IDP is particularly relevant for semi-structured and unstructured data.
Information that does not follow a predefined data model and is not directly machine-readable, such as free-form text in emails, scans, handwritten notes, or images. According to industry estimates, unstructured data accounts for the majority of corporate data. Automating its processing is the central challenge and, at the same time, the core competency of modern IDP systems.
In the IDP context, validation refers to the automated checking of extracted data for plausibility, completeness, and consistency. Typical validation steps: comparison with ERP master data (is the supplier known?), arithmetic check (does net + VAT = gross?), formal completeness check (are all required fields present?). If validation errors occur, the system escalates the issue for manual review.
A learning mechanism in IDP systems in which the model learns at the level of individual suppliers (vendors) and refines posting suggestions based on that specific supplier’s posting history. Unlike global ML models, vendor-level learning takes into account supplier-specific characteristics such as typical cost centers, accounts, or approval levels.
The system-supported control and execution of business processes according to defined rules and procedures. In the IDP context, workflow automation encompasses the automatic forwarding of documents after processing: to the responsible approvers, to accounting systems, to archiving solutions, or—in the event of discrepancies—to manual reviewers. Workflow automation serves as the bridge between IDP (data capture) and ERP/FIBU (data processing).
IDP and Related Technologies: Distinctions
IDP is often mentioned in conjunction with or in comparison to related technologies. The following table provides clarity.
| Acronym | Brief Definition | Relationship to IDP |
|---|---|---|
| OCR | Optical Character Recognition: reads characters from images/scans | OCR is a component of IDP, not the other way around. IDP understands what OCR merely reads. |
| RPA | Robotic Process Automation: automates rule-based, structured tasks | RPA and IDP complement each other: IDP provides structured data; RPA processes it further. |
| DMS | Document Management System: stores, manages, and archives documents | IDP actively processes documents; a DMS records the results. Both can be combined. |
| ERP | Enterprise Resource Planning: integrated operating system for accounting, purchasing, etc. | IDP delivers data to the ERP. It does not replace the ERP, but rather reduces the burden on its manual data entry processes. |
| ECM | Enterprise Content Management: comprehensive system for content and process control | IDP is often a subcomponent or supplement to an ECM system. |
Typical Use Cases for Intelligent Document Processing
IDP is relevant across all industries wherever large volumes of business documents are regularly processed. The following use cases are particularly common:
- Invoice processing: Automatic capture, verification, account assignment, and approval of supplier invoices in all input formats (paper, PDF, XML, XRechnung, ZUGFeRD).
- Travel and expense reporting: Receipts are photographed or uploaded, and AI automatically extracts the amount, date, category, and VAT.
- Order confirmations: Automatic reconciliation of supplier confirmations with order data. Discrepancies in price, quantity, or delivery date are immediately detected.
- Delivery notes and waybills: Automatic reconciliation of incoming goods and archiving.
- Contract management: Extraction of contract terms, notice periods, and conditions from complex legal documents.
- HR documents: Digital personnel files, onboarding documents, and references.
Intelligent Document Processing and Data Protection: GDPR Basics
The use of AI-based IDP systems inevitably raises data protection issues, particularly when language models (LLMs) utilize external cloud services. The following aspects are relevant for companies in the DACH region:
- Data Residency: Where are documents and extracted data processed? Within the EU or outside it? The GDPR requires processing within the EU legal jurisdiction or adequate protection.
- Training Use: Is company data (invoices, supplier data, terms and conditions) used to train public AI models? Reputable providers rule this out.
- Audit Trail: Is every processing step traceable and documented? Audit trail requirements are mandated by law.
- Data Processing: IDP providers that process personal or business-sensitive data are generally classified as data processors within the meaning of Art. 28 GDPR.
- Access controls: Which users are authorized to view which documents and data? Role-based access control is best practice.
The specific assessment in each individual case is the responsibility of the company and, where applicable, its data protection officer.
Conclusion: Understanding IDP to Use It Effectively
Intelligent document processing is not a single product or a single technology. It is an interplay of OCR, machine learning, NLP, LLMs, and agentic AI, which delivers very different results depending on the level of implementation.
Those familiar with these terms can better assess what a provider really means when they speak of “AI-powered processing” and which questions should be asked during the evaluation process. After all, the difference between a system that recognizes characters and one that understands documents and independently controls processes is significant in practice: in terms of turnaround times, error rates, and the actual degree of automation achievable.
Additional Resources
- free-com Blog:
- Our Intelligent Document Processing Solutions:
- Digital Invoice Processing
- Travel and Expense Reporting
- Digital Order Confirmation
- Document Recognition
FAQ: Frequently Asked Questions About IDP Intelligent Document Processing
Do You Have Any Questions For Us?
Whether delivery receipts, order confirmations, incoming invoices, expense reports or other types of documents – our intelligent solution automatically reads all company documents and enables a transparent, location-independent approval process.
We would be happy to advise you in a short, non-binding online appointment!