IDP – Intelligent Document Processing
Inhalt
- Definition von Intelligent Document Processing
- Herkunft: Wie entstand IDP?
- Die Kernkomponenten von IDP
- Wie funktioniert Intelligent Document Processing? Der Prozess in 6 Schritten
- Wichtige IDP-Begriffe von A-Z
- IDP und verwandte Technologien: Abgrenzung
- Typische Anwendungsfälle von Intelligent Document Processing
- Intelligent Document Processing und Datenschutz: DSGVO-Grundlagen
- Fazit: IDP verstehen, um IDP richtig einzusetzen
- Weiterführende Ressourcen
- FAQ: Häufige Fragen zum IDP Intelligent Document Processing
Inhalt
- Definition von Intelligent Document Processing
- Herkunft: Wie entstand IDP?
- Die Kernkomponenten von IDP
- Wie funktioniert Intelligent Document Processing? Der Prozess in 6 Schritten
- Wichtige IDP-Begriffe von A-Z
- IDP und verwandte Technologien: Abgrenzung
- Typische Anwendungsfälle von Intelligent Document Processing
- Intelligent Document Processing und Datenschutz: DSGVO-Grundlagen
- Fazit: IDP verstehen, um IDP richtig einzusetzen
- Weiterführende Ressourcen
- FAQ: Häufige Fragen zum IDP Intelligent Document Processing
Definition von Intelligent Document Processing
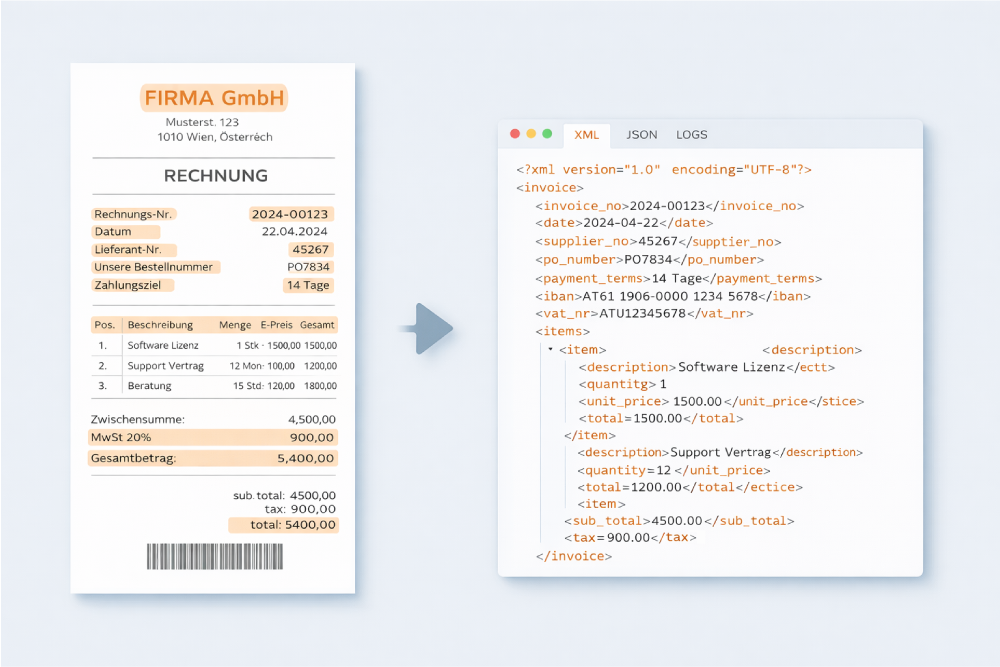
Intelligent Document Processing (IDP, dt.: intelligente Dokumentenverarbeitung) bezeichnet den Einsatz von KI-Technologien zur automatisierten Erfassung, Klassifizierung, Extraktion, Validierung und Weiterverarbeitung von Daten aus strukturierten, halbstrukturierten und unstrukturierten Dokumenten. IDP kombiniert Verfahren wie OCR, Machine Learning, Natural Language Processing (NLP) und Large Language Models (LLMs), um Dokumente nicht nur maschinell zu lesen, sondern ihren Inhalt zu verstehen und in Geschäftsprozesse zu übertragen.
IDP ist damit mehr als reine Texterkennung. Es umfasst den gesamten Verarbeitungspfad von der Dokumentenerfassung bis zur Integration in nachgelagerte Systeme wie ERP-, FIBU oder Archivlösungen. Im Unterschied zu klassischen OCR-Systemen oder regelbasierten Automatisierungstools kann IDP mit variablen Layouts, unbekannten Formaten und unstrukturierten Inhalten umgehen.
Synonyme und verwandte Begriffe: IDP wird auch als „intelligente Dokumentenverarbeitung“, „KI-Dokumentenautomatisierung“ oder im weiten Sinne als „Intelligent Document Automation“ bezeichnet.
Herkunft: Wie entstand IDP?
IDP ist kein Produkt eines einzelnen Entwicklungssprungs, sondern das Ergebnis einer mehrere Jahrzehnte langen technologischen Evolution. Der Ausgangspunkt liegt in der optischen Zeichenerkennung (OCR), die bereits in den 1960er Jahren entwickelt wurde, um gedruckten Text maschinell lesbar zu machen.
| Zeitraum der Entwicklung | Entwicklungsschritt |
|---|---|
| 1960er Jahre | Erste OCR-Systeme: zeichenbasierte Texterkennung aus gescannten Vorlagen. Sehr begrenzte Genauigkeit, abhängig von Schrifttyp und Auflösung. |
| 1990er Jahre | Verbesserung der OCR-Präzision durch statistische Methoden. Erste kommerzielle Systeme zur automatischen Dokumentenerfassung (Capture) entstehen. |
| 2000er Jahre | Machine Learning ermöglicht lernfähige Erkennungsmodelle. Erste IDP-Vorläufer für strukturierte Dokumenttypen (z.B. Rechnungen fester Lieferanten). |
| 2010er Jahre | Deep Learning und NLP verbessern Kontextverständnis erheblich. IDP-Plattformen entstehen als eigenständige Produktkategorie. |
| Ab 2022 | Large Language Models (LLMs) revolutionieren die Dokumentenverarbeitung: semantisches Verständnis ohne vorheriges Training auf Dokumenttypen. Agentic AI ergänzt IDP um proaktive Prozessteuerung. |
Die Kernkomponenten von IDP
IDP ist kein monolithisches System, sondern eine Kombination mehrerer KI-Technologien. Die folgende Übersicht beschreibt jede Komponente definitorisch.
OCR: Optical Character Recognition
OCR bezeichnet die maschinelle Erkennung von gedrucktem oder handgeschriebenen Text aus Bilddateien oder gescannten Dokumenten und die Umwandlung in maschinenlesbaren Text. Klassische OCR arbeitet zeichenbasiert und hat kein Inhaltsverstehen. Sie ist die technische Grundlage von IDP, aber nicht mit IDP gleichzusetzen. Moderne „intelligente OCR“ kombiniert klassische Texterkennung mit KI-Methoden, um Genauigkeit und Layoutflexibilität zu erhöhen. Mehr über die Entwicklung und den aktuellen Stand von OCR haben wir im Beitrag „OCR aus unterschiedlichen Blickwinkeln“ beschrieben.
ML: Machine Learning
Machine Learning ist ein Teilgebiet der KI, bei dem Systeme aus Beispieldaten lernen, anstatt explizit programmiert zu werden. Im IDP-Kontext wird ML eingesetzt, um Dokumenttypen zu klassifizieren, häufig vorkommende Felder zu erkennen und Extraktionsergebnisse über Zeit zu verbessern. ML-Modelle benötigen in der Regel eine Trainingsphase pro Dokumenttyp. Sie sind präzise bei bekannten Formaten, aber anfällig bei unbekannten oder veränderten Layouts.
NLP: Natural Language Processing
Natural Language Processing bezeichnet Methoden der KI, die es Computern ermöglichen, menschliche Sprache zu verstehen, zu analysieren und zu erzeugen. Im IDP-Kontext wird NLP eingesetzt, um semantische Zusammenhänge in Dokumenten zu erfassen: Welche Art von Dokument liegt vor? Was bedeutet ein bestimmter Textabschnitt im Gesamtkontext? NLP bildet die Brücke zwischen zeichenbasierter Erkennung (OCR) und inhaltlichem Verstehen (LLM).
LLM: Large Language Model
Large Language Models (LLMs) sind KI-Modelle, die auf sehr großen Textkorpora trainiert wurden und dadurch natürliche Sprache und Kontext auf einem deutlich höheren Niveau verstehen als klassische ML- oder NLP-Modelle. Im IDP-Kontext ermöglichen LLMs die Verarbeitung unbekannter Dokumentlayouts ohne vorheriges Training, das semantisch korrekte Erkennen von Feldinhalten (z. B. «exkl. MwSt.» = Nettobetrag), die Interpretation mehrdeutiger oder unstrukturierter Textstellen sowie die Beantwortung von Fragen über Dokumente in natürlicher Sprache. Bekannte LLMs sind GPT-4 (OpenAI), Claude (Anthropic), Gemini (Google) und verschiedene Open-Source-Modelle.
Agentic AI
Agentic AI bezeichnet KI-Systeme, die nicht nur auf Anfragen reagieren, sondern proaktiv Entscheidungen treffen, Aufgaben planen und eigenständig Folgeprozesse in Gang setzen. Im IDP-Kontext bedeutet das: Das System erkennt ein eingehendes Dokument, leitet es klassifiziert weiter, prüft automatisch auf Abweichungen, gibt bei Regelkonformität ohne manuellen Eingriff frei und eskaliert gezielt bei Ausnahmen. Agentic AI repräsentiert die aktuell höchste Entwicklungsstufe der IDP-Technologie.

Wie funktioniert Intelligent Document Processing? Der Prozess in 6 Schritten
Ein vollständiger IDP-Prozess umfasst typischerweise die folgenden Phasen. Je nach Lösung und Anwendungsfall können einzelne Schritte kombiniert oder erweitert werden.
Lösungen zur intelligenten Dokumentenautomatisierung
Wichtige IDP-Begriffe von A-Z
Die folgende Zusammenstellung definiert die wichtigsten Fachbegriffe, die im Kontext von IDP regelmäßig auftauchen.
KI-Systeme, die proaktiv und autonom Entscheidungen treffen und Prozesse anstoßen, ohne auf jeden Einzelschritt manuell hingewiesen werden zu müssen. Im IDP-Kontext steuert Agentic AI den gesamten Dokumentendurchlauf eigenständig, von der Erkennung über die Validierung bis zur Archivierung.
Oberbegriff für die automatisierte Erfassung und Interpretation von Geschäftsbelegen (Rechnungen, Spesenbelege, Auftragsbestätigungen, Lieferscheine etc.) durch KI-gestützte Systeme. Umfasst Texterkennung, Klassifizierung, Feldextraktion und Validierung. Wird häufig synonym mit IDP für dokumentenbasierte Buchhaltungs- und Beschaffungsprozesse verwendet.
Teilgebiet der KI, das Computern die Interpretation von Bildinhalten ermöglicht. Im IDP-Kontext wird Computer Vision eingesetzt, um Dokumentlayouts zu analysieren, Tabellen zu erkennen, Felder zu lokalisieren und Bilder oder Stempel innerhalb von Dokumenten zu verarbeiten. Computer Vision ergänzt OCR um die visuelle Strukturerkennung.
Der Prozess, bei dem relevante Informationen aus einem Dokument automatisch identifiziert und in ein strukturiertes Format übertragen werden. In IDP-Systemen umfasst Datenextraktion sowohl die Erkennung bekannter Felder (z. B. Rechnungsnummer, Betrag, Datum) als auch das kontextuelle Verstehen unbekannter Dokumentstrukturen.
Verwandte Begriffe: Feldextraktion, Key-Value-Extraktion, Named Entity Recognition (NER)
Die automatische Einstufung eines Dokuments in eine vordefinierte Kategorie (z. B. Eingangsrechnung, Auftragsbestätigung, Lieferschein, Spesenbeleg). IDP-Systeme nutzen dafür Kombination aus Inhaltsanalyse (NLP), visueller Strukturerkennung (Computer Vision) und gelernten Mustern (ML). Eine korrekte Klassifizierung ist Voraussetzung für alle nachfolgenden Verarbeitungsschritte.
Bezeichnung für Geschäftsprozesse, die vollständig automatisiert und ohne manuellen Eingriff im Hintergrund ablaufen („im Dunkeln“), ohne dass ein:e Sachbearbeiter:in den Vorgang sieht oder steuert. Ursprünglich aus der Versicherungswirtschaft stammend, ist Dunkelverarbeitung heute ein zentrales Ziel jedes IDP-Projekts. Der Anteil vollautomatisch verarbeiteter Vorgänge wird als «Dunkelverarbeitungsquote» gemessen. Teilautomatisierte Prozesse, bei denen Menschen an definierten Ausnahmepunkten eingreifen, werden gelegentlich als «graue Verarbeitung» bezeichnet.
Kennzahl, die angibt, welcher prozentuale Anteil eingehender Dokumente vollständig ohne manuellen Eingriff (also in Dunkelverarbeitung) vom Eingang bis zur Buchung/Archivierung verarbeitet wird. Eine hohe Dunkelverarbeitungsquote ist das primäre Ziel von IDP-Implementierungen. Sie ist zu unterscheiden von der Erkennungsrate (Anteil korrekt erkannter Felder) und der Automatisierungsrate (Anteil automatisierter Prozessschritte).
Bezeichnet die vollständige Automatisierung eines Geschäftsprozesses, vom Dokumenteneingang über alle Verarbeitungsschritte bis zur Integration in Zielsysteme und revisionssicheren Archivierung, ohne Medienbruch oder manuelle Zwischenschritte. Im Kontext von IDP ist End-to-End-Automatisierung der Maßstab, an dem Lösungen gemessen werden.
Sprachmodell, das auf sehr großen Textmengen trainiert wurde und dadurch natürliche Sprache auf semantischer Ebene versteht. LLMs können Texte generieren, zusammenfassen, klassifizieren und Fragen beantworten. Im IDP-Einsatz ermöglichen sie die Verarbeitung unbekannter Layouts und kontextbasiertes Verstehen von Dokumentinhalten ohne vorheriges Dokumenten-spezifisches Training. Bekannte LLMs: GPT (OpenAI), Claude (Anthropic), Gemini (Google).
Qualitätssicherungsprinzip in der KI-gestützten Dokumentenverarbeitung: Mehrere Sprachmodelle (LLMs) verarbeiten dasselbe Dokument unabhängig voneinander. Nur wenn alle oder eine definierte Mehrheit der Modelle zum selben Ergebnis kommt, wird das Ergebnis als verifiziert markiert und automatisiert weitergeleitet. Bei abweichenden Ergebnissen erfolgt eine gezielte Eskalation zur manuellen Prüfung. Das Konsensprinzip erhöht die Zuverlässigkeit der Dunkelverarbeitung erheblich.
Teilgebiet der künstlichen Intelligenz. ML-basierte Systeme lernen aus Beispieldaten. Statt fester Regeln erkennen sie Muster auf dem Dokumentenlayout und können dieses gut auslesen, solange sich das Dokument an die bekannten Muster hält. Im IDP-Kontext eingesetzt für Dokumentenklassifizierung, Feldextraktion aus bekannten Templates und kontinuierliche Verbesserung der Erkennungsqualität durch Nutzerfeedback.
Unterbrechung eines Informationsflusses durch den Wechsel von einem Medium oder System in ein anderes, der eine manuelle Dateneingabe erfordert. Beispiel: Eine PDF-Rechnung wird per E-Mail empfangen, aber manuell in das ERP-System übertragen. Die Freiheit von jeglichen Medienbrüchen ist ein zentrales Ziel von IDP-Lösungen.
Teilgebiet der KI zur maschinellen Verarbeitung und Analyse menschlicher Sprache. NLP-Methoden ermöglichen die Erkennung von Textstrukturen, semantischen Beziehungen und sprachlichen Bedeutungen. Im IDP-Kontext bildet NLP die Grundlage für das inhaltliche Verstehen von Dokumenten über die reine Zeichenerkennung hinaus.
Technologie zur Umwandlung von gedrucktem oder handgeschriebenem Text aus Bilddateien oder Scans in maschinenlesbaren Text. Klassische OCR arbeitet zeichenbasiert ohne inhaltliches Verständnis. Moderne «intelligente OCR» integriert KI-Methoden, um Genauigkeit und Flexibilität zu erhöhen. OCR ist eine notwendige Komponente von IDP, aber allein kein ausreichendes Instrument für komplexe Dokumentenprozesse.
Weiterführend: Unser Beitrag „OCR Texterkennung aus unterschiedlichen Blickwinkeln“
Aufbewahrung von Geschäftsdokumenten in einer Form, die spätere Veränderungen ausschließt und die Anforderungen an Buchführung und Compliance erfüllt. In Deutschland und Österreich sind die Grundsätze ordnungsmäßiger Buchführung (GoB) sowie die GoBD (Deutschland) und österreichische BAO maßgeblich. Revisionssichere Archivierung ist typischerweise das letzte Glied eines IDP-Prozesses.
Technologie zur Automatisierung regelbasierter, repetitiver Aufgaben durch Software-Roboter (Bots), die Benutzeraktionen in digitalen Systemen nachahmen. RPA arbeitet optimal mit strukturierten Daten und klar definierten Regeln. IDP und RPA ergänzen sich: IDP wandelt unstrukturierte Dokumente in strukturierte Daten um, RPA verarbeitet diese Daten weiter. RPA kann keine unstrukturierten Inhalte selbst interpretieren.
IDP ist nicht RPA! RPA ist regelbasiert, IDP ist lernfähig und kontextbasiert.
Daten, die in einem definierten, maschinenlesbaren Format vorliegen, z. B. XML, JSON oder Datenbankfelder. Strukturierte Rechnungsformate wie XRechnung oder ZUGFeRD liefern strukturierte Daten. IDP ist besonders relevant für halbstrukturierte und unstrukturierte Daten.
Informationen, die kein vordefiniertes Datenmodell aufweisen und nicht direkt maschinenlesbar sind, z. B. Freitexte in E-Mails, Scans, handschriftliche Notizen oder Bilder. Unstrukturierte Daten machen laut Branchenschätzungen den Großteil der Unternehmensdaten aus. Ihre automatisierte Verarbeitung ist die zentrale Herausforderung und gleichzeitig die Kernkompetenz moderner IDP-Systeme.
Im IDP-Kontext bezeichnet Validierung die automatisierte Prüfung extrahierter Daten auf Plausibilität, Vollständigkeit und Konsistenz. Typische Validierungsschritte: Abgleich mit ERP-Stammdaten (Lieferant bekannt?), rechnerische Prüfung (stimmt Netto + MwSt. = Brutto?), formale Vollständigkeitsprüfung (alle Pflichtfelder vorhanden?). Bei Validierungsfehlern eskaliert das System zur manuellen Prüfung.
Lernmechanismus in IDP-Systemen, bei dem das Modell auf Ebene einzelner Lieferanten (Kreditoren) lernt und Buchungsvorschläge auf Basis der Buchungshistorie dieses spezifischen Lieferanten verfeinert. Im Gegensatz zu globalen ML-Modellen berücksichtigt Vendor-Level Learning lieferantenspezifische Besonderheiten wie typische Kostenstellen, Konten oder Freigabestufen.
Die systemgestützte Steuerung und Ausführung von Geschäftsprozessen nach definierten Regeln und Abläufen. Im IDP-Kontext umfasst Workflow-Automatisierung die automatische Weiterleitung von Dokumenten nach der Verarbeitung: an zuständige Freigeber, an Buchhaltungssysteme, an Archivlösungen oder bei Abweichungen an manuelle Prüfer. Workflow-Automatisierung ist die Brücke zwischen IDP (Datengewinnung) und ERP/FIBU (Datenverarbeitung).
IDP und verwandte Technologien: Abgrenzung
IDP wird häufig zusammen mit oder im Vergleich zu verwandten Technologien genannt. Die folgende Tabelle schafft Klarheit.
| Akronym | Kurzdefinition | Verhältnis zu IDP |
|---|---|---|
| OCR | Optical Character Recognition: liest Zeichen aus Bildern/Scans | OCR ist eine Komponente von IDP, nicht umgekehrt. IDP versteht, was OCR nur liest. |
| RPA | Robotic Process Automation: automatisiert regelbasierte, strukturierte Aufgaben | RPA und IDP ergänzen sich: IDP liefert strukturierte Daten, RPA verarbeitet sie weiter. |
| DMS | Dokumentenmanagementsystem: speichert, verwaltet und archiviert Dokumente | IDP bearbeitet Dokumente aktiv; ein DMS nimmt die Ergebnisse auf. Beides kann kombiniert werden. |
| ERP | Enterprise Resource Planning: integriertes Betriebssystem für Buchhaltung, Einkauf etc. | IDP liefert Daten an das ERP. Es ersetzt das ERP nicht, sondern entlastet dessen manuelle Eingabeprozesse. |
| ECM | Enterprise Content Management: umfassendes System für Inhalts- und Prozesssteuerung | IDP ist oft eine Teilkomponente oder Ergänzung eines ECM-Systems. |
Typische Anwendungsfälle von Intelligent Document Processing
IDP ist branchenunabhängig überall dort relevant, wo regelmäßig große Mengen an Geschäftsdokumenten verarbeitet werden. Die folgenden Anwendungsfälle sind besonders verbreitet:
- Eingangsrechnungsverarbeitung: Automatische Erfassung, Prüfung, Kontierung und Freigabe von Lieferantenrechnungen in allen Eingangsformaten (Papier, PDF, XML, XRechnung, ZUGFeRD).
- Reisekosten- und Spesenabrechnung: Belege werden fotografiert oder hochgeladen, KI extrahiert Betrag, Datum, Kategorie und MwSt. automatisch.
- Auftragsbestätigungen: Automatischer Abgleich von Lieferantenbestätigungen mit Bestelldaten. Abweichungen bei Preis, Menge oder Lieferdatum werden sofort erkannt.
- Lieferscheine und Frachtbriefe: Automatischer Wareneingangsabgleich und Archivierung.
- Vertragsmanagement: Extraktion von Vertragslaufzeiten, Kündigungsfristen und Konditionen aus komplexen juristischen Dokumenten.
- Personalunterlagen (HR): Digitale Personalakten, Onboarding-Dokumente, Zeugnisse.
Intelligent Document Processing und Datenschutz: DSGVO-Grundlagen
Der Einsatz von KI-basierten IDP-Systemen wirft zwangsläufig datenschutzrechtliche Fragen auf, insbesondere wenn Sprachmodelle (LLMs) externe Cloud-Dienste nutzen. Für Unternehmen im DACH-Raum sind folgende Aspekte relevant:
- Datenresidenz: Wo werden Dokumente und extrahierte Daten verarbeitet? In der EU oder außerhalb? DSGVO schreibt EU-Rechtsraum oder adäquaten Schutz vor.
- Trainingsnutzung: Werden Unternehmensdaten (Rechnungen, Lieferantendaten, Konditionen) zum Training von öffentlichen KI-Modellen verwendet? Seriöse Anbieter schließen das aus.
- Audit-Trail: Ist jeder Verarbeitungsschritt nachvollziehbar und dokumentiert? Revisionssicherheit ist gesetzlich vorgeschrieben.
- Auftragsverarbeitung: IDP-Anbieter, die personenbezogene oder geschäftssensible Daten verarbeiten, sind in der Regel als Auftragsverarbeiter i. S. d. Art. 28 DSGVO einzustufen.
- Zugriffskontrollen: Welche Nutzer dürfen welche Dokumente und Daten einsehen? Rollenbasierte Zugriffskontrolle ist Best Practice.
Die konkrete Einschätzung im Einzelfall obliegt Unternehmen und ggf. ihren Datenschutzbeauftragten.
Fazit: IDP verstehen, um IDP richtig einzusetzen
Intelligente Dokumentenverarbeitung ist kein einzelnes Produkt und keine einzelne Technologie. Es ist ein Zusammenspiel aus OCR, Machine Learning, NLP, LLMs und Agentic AI, das je nach Ausbaustufe sehr unterschiedliche Ergebnisse liefert.
Wer die Begriffe kennt, kann besser einschätzen, was ein Anbieter wirklich meint, wenn er von „KI-gestützter Verarbeitung“ spricht und welche Fragen im Evaluierungsprozess gestellt werden sollten. Denn der Unterschied zwischen einem System, das Zeichen erkennt, und einem System, das Dokumente versteht und Prozesse eigenständig steuert, ist in der Praxis erheblich: in Durchlaufzeiten, Fehlerquoten und dem tatsächlich erreichbaren Automatisierungsgrad.
Weiterführende Ressourcen
- free-com Ratgeber:
- Unsere Lösungen mit intelligenter Dokumentenverarbeitung:
FAQ: Häufige Fragen zum IDP Intelligent Document Processing
Haben Sie Fragen an uns?
Egal ob Lieferscheine, Auftragsbestätigungen, Eingangsrechnungen, Spesenabrechnungen oder andere Belegarten – unsere intelligente Lösung liest alle Unternehmensdokumente automatisch aus und ermöglicht einen transparenten, ortsunabhängigen Freigabeprozess.
Wir beraten Sie gerne im Rahmen eines kurzen, unverbindlichen Online-Termins!