OCR: Text Recognition from Different Perspectives
Veröffentlicht am 14.04.2026
Lesedauer: 10 min
Contents
- What is OCR?
- The Historical Development of OCR Text Recognition
- How has OCR Evolved in Recent Years?
- How Does OCR Text Recognition Work?
- What are the Benefits of OCR?
- Interesting Use Cases for Text Recognition
- What Role Does OCR Play at free-com?
- Successful Projects Using our OCR Text Recognition
- Benefits for Our Customers
- Conclusion: OCR, a Technology That Offers Many Advantages
- FAQs: Frequently Asked Questions About OCR and Text Recognition
Inhalt
- What is OCR?
- The Historical Development of OCR Text Recognition
- How has OCR Evolved in Recent Years?
- How Does OCR Text Recognition Work?
- What are the Benefits of OCR?
- Interesting Use Cases for Text Recognition
- What Role Does OCR Play at free-com?
- Successful Projects Using our OCR Text Recognition
- Benefits for Our Customers
- Conclusion: OCR, a Technology That Offers Many Advantages
- FAQs: Frequently Asked Questions About OCR and Text Recognition
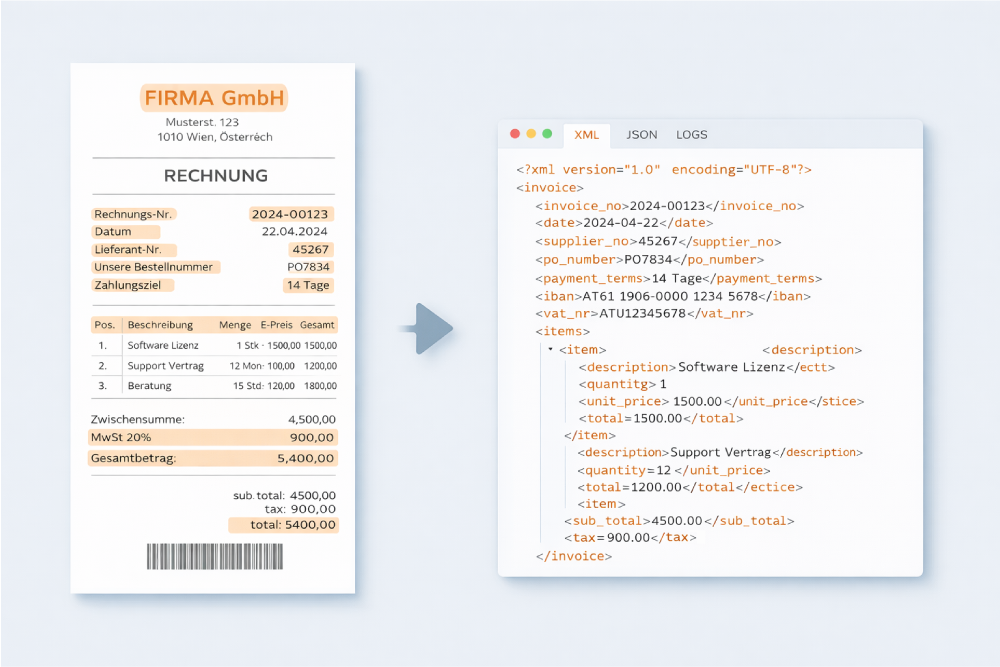
Whether it’s an invoice, delivery note, order confirmation, or scanned document: businesses still have a wealth of information stored in documents that, while available in digital form, initially consist of nothing more than pixels to systems. This is exactly where OCR comes into play.
OCR stands for Optical Character Recognition. It converts images, scans, or image-based PDFs into machine-readable data. This allows content to be processed, analyzed, and located automatically.
For businesses, this is not a minor technical detail, but a key driver for more efficient processes. In the past, data had to be manually typed, transferred, and verified; today, however, OCR can enable direct integration into a fully digital workflow. But: pure text recognition is not enough.
Modern platforms combine OCR with AI, layout recognition, table analysis, and structured data extraction. This allows not only letters or lines to be recognized, but also paragraphs, tables, key-value pairs, or document structures. While the term “OCR text recognition” is still accurate today, it falls somewhat short in modern business applications.
This guide provides insight into developments in OCR technology, highlights the technological evolution of recent years, and demonstrates how companies can massively increase their efficiency through OCR text recognition. We are building a bridge from the early days all the way to the AI-powered systems we are using at free-com in 2026.
What is OCR?
OCR stands for Optical Character Recognition. It is a technology that enables the conversion of unstructured data into machine-readable, i.e., structured, data. Without this step, scans, photos, or image-based PDF files would be nothing more than static images composed of black and white pixels to a computer.
OCR recognizes letters, combines them into words, and identifies entire sentences. Thus, usable information is extracted from the image in the form of machine-readable text, which can then be interpreted, automatically processed, searched, and analyzed by any system.
OCR is therefore the foundation for integrating documents and the data they contain into a company’s business processes. This requires:
- Hardware: A scanner or camera to digitize physical documents if they are not available as (imported) files.
- Software: An OCR program (or an API) that processes the visual information and translates it into machine code (e.g., ASCII).
The Historical Development of OCR Text Recognition
OCR text recognition originated long before the computer age: as early as 1914, Emanuel Goldberg developed a machine that reads characters and converts them into standard telegraph code. In the 1920s and 1930s, Gustav Tauschek obtained patents in Germany for a “reading machine” based on optical stencils.
In the 1950s, OCR began to gain prominence as a commercial technology. Initially, it was used in very specific applications such as banking and mail sorting. In the 1960s, specially designed OCR-A and OCR-B fonts ensured that machines could read text more reliably.
An important milestone followed in 1974: Ray Kurzweil developed the first commercial OCR system capable of reading any font. Originally intended as a reading aid for the blind, it contributed significantly to the widespread commercialization of paper-based text digitization.
From the 1990s through the 2010s, the technology became widely available, though it remained heavily reliant on clear typefaces and predefined templates.
How has OCR Evolved in Recent Years?
Over the past five years, the technology has made significant strides. While traditional OCR was character-based, modern AI-based OCR now uses neural networks and deep learning.
- Contextual understanding: Modern systems don’t just “read” letters; they understand the context. They can distinguish an IBAN from a phone number, even when the layout varies. This allows content to be classified much more accurately.
- Handwriting recognition (ICR): The error rate for handwritten text has dropped dramatically thanks to AI models.
- LLM integration: Since 2023/2024, Large Language Models (LLMs) have been integrated to immediately validate and semantically structure the extracted data.
These advancements make a fundamental difference, particularly when it comes to invoices, forms, receipt, and other complex business documents. They form the technical foundation for significantly greater automation, reduced manual verification efforts, and a noticeably lower error rate in document-based business processes.
How Does OCR Text Recognition Work?
The process of converting an image to text involves several specialized steps:
OCR in Action
What are the Benefits of OCR?
- Significant time savings: Manual data entry is eliminated. Documents that used to take a few minutes to process are now scanned in a fraction of a second.
- Lower error rate: Manual transcription errors are eliminated. Modern software solutions achieve recognition rates of over 99%.
- Searchability & archiving: By converting documents into structured text, they can be found within seconds—a must for compliance and GoBD-compliant archiving.
- Better data foundation: Structured data can be systematically analyzed, standardized, and transferred to downstream processes. This enables extensive automation and provides a solid foundation for analyzing all workflows and processing procedures.
- Scalability: Modern solutions process not only printed text but often also handwriting, tables, layouts, receipts, and forms. This significantly expands the benefits across many document types. The number of documents to be scanned is freely scalable without significant additional effort for companies.
- Positive Effects: OCR serves as a foundation for streamlining workflows, automating processes, and increasing productivity. Faster decision-making and lower costs are just a few of the positive effects that ripple through the entire workflow.
Interesting Use Cases for Text Recognition
OCR is used in nearly every industry, from logistics to healthcare. Typical use cases include intelligent searches in document archives, the automated processing of forms, and the extraction of data from patient records, bank documents, contracts, delivery notes, invoices, or labels.
For free-com, the focus is on document-based processes in accounting, procurement, HR, logistics, and sales. This is where the practical value of OCR becomes very clear: documents arrive via various channels, contain semi-structured or unstructured information, and yet must be processed quickly, accurately, and in a traceable manner. This is precisely where OCR can demonstrate its strengths—provided it is combined with validation, workflow, and system integration.
What Role Does OCR Play at free-com?
At free-com, OCR is not a standalone technology but rather part of a larger system. Some of the use cases and document types that are processed include:
- Incoming Invoices: During invoice recognition, incoming invoices are processed using AI-powered OCR from PDF, scanned, or image files, and relevant data is automatically extracted. This includes, among other things, order numbers, delivery note numbers, tax rates, master data, discount periods, payment terms, header and line item data, as well as gross and net amounts. The data is then automatically transferred to the subsequent approval workflow, which is conducted entirely digitally. The process is rounded out by digital, audit-proof archiving—all without any media discontinuity.
- Order Confirmations: Order confirmations are a classic use case for automatic text recognition. At free-com, incoming order confirmations are digitally captured regardless of the channel through which they are received. Relevant header and line item data, such as item numbers, quantities, prices, or delivery dates, are extracted. This is particularly relevant in purchasing and supply chain management because discrepancies can be detected early and processes can continue without any media discontinuity.
- Travel and Expense Reporting: OCR also plays a key role in travel and expense reporting. Receipts can be photographed directly on the go using a smartphone and saved via email or uploaded as a PDF. The solution automatically reads the documents and extracts relevant information for later processing, including the receipt’s origin, tax rates, currency conversion, and gross and net amounts.
- Other types of receipts: Through the use of AI and machine learning, all document types can be read without prior training on the layout. These include, for example, delivery notes, waybills, timesheets, or material certificates. But all other individual documents within a company can also be automated.
Successful Projects Using our OCR Text Recognition




Benefits for Our Customers
Seamless Integration
Seamless integration with all common financial accounting and ERP systems
Scalability
Whether it’s 100 or 100,000 documents a month, performance remains consistent
Compliance
Greater compliance and better adherence to internal policies
Conclusion: OCR, a Technology That Offers Many Advantages
In 2026, OCR remains a core technology for digital document processing. It converts scans, photos, and image-based PDFs into usable data, thereby laying the foundation for search, editing, analysis, and automation. For businesses, this is particularly relevant in areas where document-based processes have previously been hindered by media discontinuities, manual data entry, and slow workflows.
Modern requirements go beyond simple text recognition. Current platforms combine OCR with handwriting recognition, layout understanding, table and field extraction, and AI-powered document analysis. This is precisely why OCR is most valuable today when it is part of a larger system—that is, when it not only extracts text but also drives business processes forward.
FAQs: Frequently Asked Questions About OCR and Text Recognition
Do You Have Any Questions For Us?
Whether delivery receipts, order confirmations, incoming invoices, expense reports or other types of documents – our intelligent solution automatically reads all company documents and enables a transparent, location-independent approval process.
We would be happy to advise you in a short, non-binding online appointment!
































